|
Begin by turning on the Trimble Series Geo7x GPS unit and open the TerraSync software on the device. Open the GPS Pathfinder Office software on your desktop computer. In order for the Pathfinder software to connect to directories on the GPS unit, a new data file must be created on the GPS unit. To do so, open the dropdown menu in the upper left corner of the TerraSync screen that should currently read “Status,” and select “Data” from the dropdown list. Name the new file in a way that indicates that it should be deleted at a later time, as the only function for this file is for the device to be able to communicate with the desk top computer. Create file and select “OK” for the default antenna height. Connect the device to the computer. In the Pathfinder program on the desktop, create a new project by clicking “New” in the Select Project window. Name the project by the last two digits of the project year followed by a dash and the three-digit project code (ex. 18-142) and browse to the projects “Trimble Exports” folder on the server for its directory location. If a Pathfinder project has already been created for this project, select it from the Project Name dropdown list and click “OK.” Next, click the Data Transfer icon located on the left side toolbar near the top of the screen or select “Data Transfer” from the Utilities dropdown list from the main menu bar. Ensure that the device is connected to the GIS Datalogger on Windows Mobile and the Receive tab is selected on the Data Transfer Window. 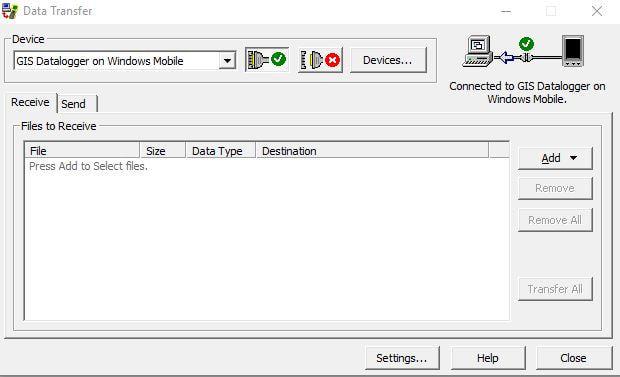 Click on the Add button and choose “Data File” from the dropdown list. In the Open window, select the file to be received from the Trimble unit and make sure the destination folder is the correct directory setting for the project. Then click “Open.” The file should now appear in the Files to Receive window. Click the Transfer All button. Depending on the size of the project, the files may take some time to transfer. When file has successfully transferred, click “Close.” The data file should now be in the project Trimble Export folder. The next step is to differentially correct the hundreds or thousands of data points collected by the GPS unit using known local datum stations to improve the accuracy and aggregate all the data points collected for each feature. Click on the Differential Collection Wizard icon located on the left side tool bar below the Data Transfer icon, or is also found in the Utilities dropdown list of the main menu bar. In the Differential Correction Wizard, make sure that the transferred data file is in the selected files to correct. The data file should now have a .ssf extension. Click “Next” three times submitting to all the defaults until the Base Data window appears. 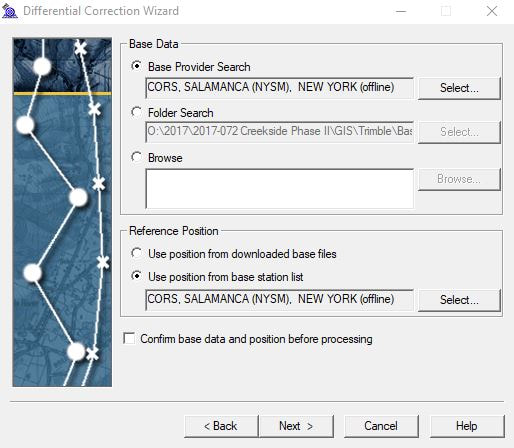 Click the Select button and choose a provider closest to the top that is not “offline” as they are ordered in proximity to where the data points were taken. 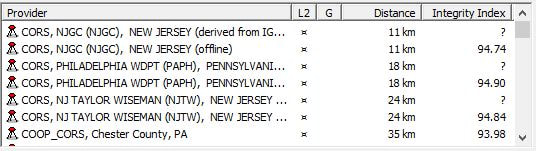 Once the base provider has been chosen, click “Next” and then “Start.” The Differential Correction Wizard will now start requesting date sensitive files from the base provider to triangulate satellite positions with known ground datum points at a specific time and return a sub-meter accurate point for each collected feature. When the differential correction is complete, click “Close.”
The next step is to export the correction files as shapefiles. Click the Export icon found on the left side toolbar below the Differential Correction Wizard icon or select Export from the Utilities dropdown list on the main menu bar. In the Export window, ensure that selected file is the differentially corrected file now with a .cor extension and that the Output Folder is the Export folder within the projects Trimble Export folder. Select ESRI Shapefile as the format in the Export Setup window and change the coordinate system to match all other GIS files of the project by clicking the “Properties” button, then click “Change.” Choose the system of US State Plane 1983 or UTM depending on the project and the appropriate zone. For either, select NAD 1983 (Conus) as the datum, then set the appropriate altitude and coordinate units for the project and click “OK.” Then click “OK” in the Export window. Click “Yes” to proceeding without an ESRI projection file, as one will be created later when the file is exported through ArcMap. When export is completed, close the window, disconnect the Trimble from the computer and close out of Pathfinder Office program. Open the project’s .mxd file and bring in the Trimble shapefiles from the Export folder of the projects Trimble Export folder through ArcCatalog. After visually inspecting for proper location, re-export the files using the coordinate reference system of the .mxd data frame and save the file to the project’s Shapefiles folder with the proper naming conventions.
0 Comments
Increasingly, slope analysis has become a more common request for projects not only for the planning of fieldwork and report production, but also for job proposals. If areas of a high percent rise in slope can be identified, then such areas can be eliminated for prospective subsurface testing thus bring potential cost estimates down and the likelihood of winning a job up. The value of such analysis is appreciating greatly from project to project.
To perform an analysis of slope using ArcGIS, the Spatial Analyst license is required. The Spatial Analyst toolset is included with the license and contains several tool kits and tools, a few of which, are used in this process. Before the use of such tools, the elevation data need to be acquired for the area of interest. Elevation data comes in many forms- LAS point cloud, TIN (Triangular Irregular Network), DTM (Digital Terrain Model) and DEM (Digital Elevation Model). For our purposes, we will stick with the Digital Elevation Model as it is now widely available and usually comes in the form of a georeferenced raster tile that it easily inserted into a project .mxd and is compatible with the toolset we will use. There are many resources online to find elevation data for your area of interest (AOI). Many websites now offer a data viewer or web map that allows you navigate to and draw your AOI and returns lists of available datasets. Below are a few links to such sites. http://gis5.oit.ohio.gov/geodatadownload/ https://coast.noaa.gov/dataviewer/#/lidar/search/ https://viewer.nationalmap.gov/advanced-viewer/ http://maps.psiee.psu.edu/ImageryNavigator/ http://maps.psiee.psu.edu/preview/map.ashx?layer=3188 In other cases, a tile index is provided in the form a shapefile and the DEM is downloaded from a list of files that match the index tile. It is often difficult to find a DEM tile that completely covers the AOI. In this case, it is necessary to download multiple tiles. Performing analysis on multiple tiles is more time consuming and cumbersome, so it is best practice to merge the tiles into one raster. This can be done by using the Mosaic To New Raster tool found in the Raster Dataset toolkit in the Data Management toolbox. Upon opening the tool window, drag the group of downloaded DEM tiles from the .mxd Table of Contents or ArcCatalog to the Input Rasters field. Set the output location to a Raster folder and name the aster dataset accordingly using a .tif extension (TIFF) as that is likely the same file type as the input rasters. Change the pixel type to 32_BIT_UNSIGNED and set the number of bands to 1. Everything else can be left to its default setting. Once the tool has run, you will have a rectangular raster with cells outside of the original tiles but within the extent of the group set to a value of 0. Now is a good time to clip this raster to a smaller size with boundaries closer to the area of interest. A buffer of you area of interest or project area at a desired distance would be a good place to start. To clip a raster you need to return to the Data Management toolbox and to the Raster Processing toolkit. There you will find a Clip tool for raster clipping. Drag the Mosaicked raster to the input raster field and the AOI buffer (or alternative) to the output extent field. Check the box that reads “Use Input Features for Clipping Geometry” and assign the output raster dataset to the raster folder of your project. The result is a raster shaped to the clipping feature, much smaller in file size and quicker to run the following processes on. Now that the elevation data has been minimized, the Spatial Analyst toolset can be used. In the Spatial Analyst toolbox open the Slope tool in the Surface toolkit. Drag the clipped DEM raster to the input raster field and set the output raster accordingly. *Important Note: When running any raster processes from the Spatial Analyst toolbox and error occurs when the output is set to save on the company server. Whenever running a raster process from this toolbox save the output to a place your desktop. It is best practice in this case to keep a “Raster Processes” folder on your desktop for such occasions. Most of these processes are interim and will likely be discarded after the final process. Set the output measurement to “PERCENT_RISE,” method to “PLANAR” and keep the z-factor as 1. It is possible that the DEM being used has different vertical measurements than horizontal, but highly unlikely. In any case, it is always a good idea to check the original metadata from the downloaded tiles to look at the unit specifications. If the DEMs vertical units do not match the horizontal units read the tools instructions for adjusting the z-factor value. The output of this process is a raster dataset that is a replica of the input raster except the cell values now represent a percent rise in slope from its neighboring cells rather than an elevation value. Do not be alarmed when you see the highest value of the raster exceed 100. One hundred percent slope would account for a 45-degree angle, as it is a one to one ratio in elevation increase. Percent rise can be measured to infinity depending on distance and increase in elevation. Next, the values within this raster need to be extracted and put into a tangible vector dataset. Before that can happen, the values must be converted into integers to minimize the possible number of values represented in the resulting vector. This is accomplished by using the Int tool that can be found in the Math toolkit of the Spatial Analyst toolbox. Simply input the slope raster and name the output by referring to the tool or process used to create it such as “IntSlope”. This, also being a raster process, must be saved locally to a computer and not on a network server. The integer output can now be converted to a vector polygon by using the Raster To Polygon tool found in the From Raster toolkit of the Conversion Tools toolbox. Depending on the size of the inputted integer based raster, this process may take a while. Set field to VALUE and keep “Simplify Polygons” checked. The output of this process is a vector polygon that can be saved to the network server in a shapefiles folder. After the slope polygon has been created, the layer can be turned off in the Table of Contents in the ArcMap document. It will take a long time for it to draw on the page and is not necessary for the next step. Open the attribute table of the resulting polygon layer and under the Table Options menu choose Select by Attributes. Create a new selection by choosing “gridcode” as the WHERE clause. The gridcode field represents the slope value for each raster cell produced by the Int and Slope tools and is now grouped by each mutipart of the polygon. Depending on the requirements for the project, the slope percentage cut off may be between 12 and 15 percent. For example, if the cut off is 15% the WHERE clause should read: “gridcode” <=15. This would select all the features within the layer that have a gridcode of 15 or less. Export the selected features as a new shapefile of areas that are of 15 percent or less slopes. Perform a similar selection by attribute with the WHERE clause as: “gridcode”>15. This will select all the features of greater than 15 percent slope. Export these selected features as a new shapefile of areas of greater than 15% slopes. The final step is to dissolve all the rows in each new polygon shapefile so that it each one is a single feature. Add an integer field to each shapefile called “dissolve”. Using the field calculator set the value for every row in this field to 1. Open the Dissolve tool found in the Generalization toolkit of the Data Management Tools toolbox or in the Geoprocessing dropdown menu on the ArcMap task bar. Input the shapefile and set he output accordingly. Choose the dissolve field you added as the dissolve field and leave everything else to default. Repeat this process with the opposite shapefile and the result is to single feature shapefiles of testable and untestable areas. It is a matter of personal preference to merge the two together as a single shapefile. Proprietary software is often like the carrot dangling from a string. Just when you think you have it, you realize there is so much you don't have. Software licensing is pretty expensive even at its base level. For a few added bells and whistles the price seems to double even if you only want a half of a bell and no whistles. Small and easily programmable features can be lumped in with higher licensing packages which can drive you mad after having spent so much money for the license you already paid for. Adding insult to injury, sometimes a portion of the tool or feature is available for use but access is denied for the rest of its functionality. Being denied the use of simple features almost seems like a way to taunt you into buying the next level. Take ArcGIS for example. Their GIS platform has many different licensing packages and tool kits that you can pay extra money for. Some complex features that took developers months or years to develop probably deserve a little extra cash. But some tools are pretty basic and can be found in opensource software. As an example the Erase tool in Arcmap is fairly basic in functionality. Its purpose is to use the shape and extent of one polygon and cut that shape out of another polygon. A simple tool, but only available in an Advanced licensing package. The Difference tool in QGIS accomplishes the same task, but for free. There are many other tools and functions such as interpolation, hillshading and statistical packages that can be found in many opensource GIS programs that you would have to pay a premium for using ArcGIS. Using opensource software does make you feel a little better inside, but its not as good a using a proprietary software's own basic tools to create work arounds to unlock the functionality of an upper tier tool. To yet again return to the ArcGIS fishnet tool, I had recently been coming across some issues with the numbering of evenly spaced grid points the fishnet tool generates as labels to accompany the grid lines or boxes. The drawing order for which goes from left to right(west to east) and bottom to top(south to north).  I often use these points to represent the locations of shovel test pits and when not using a localized coordinate system to assign them coordinate labels, they need to be labeled either numerically, alphabetically or a combination of the two. Usually this drawing order is fine as arbitrary and labels are generated using a python incrementation script in the field calculator that by default ascend by way of the drawing order. Recently, however, I had been asked to create alphanumeric labels for a large number of shovel test pits that were ordered the in another direction like reading a book. My first thought was "Oh, that's easy. Ill just rotate the grid upside down." I smacked myself in the forehead and quickly realized that that wouldn't work. No matter how the grid was rotated, the drawing order would never appear to be like words in a book. My next thought was to search the tool boxes and quickly found the applicably named Sort Tool. On the surface the tool looked amazing. You can create fields on which to sort the drawing order of your points, lines or polygons of a multipart feature. You could even base the sort on multiple field characteristics or even by its x/y geometry, that is, if you had an advanced license. Without it, you can only sort by one field and the tool will also recognize if that field is a calculated geometry and denies permission of functionality. What a wall. Sorting by x/y geometry would be the best solution around my dilemma and there still had to be a way by using this tool. Somehow I needed to reverse the values of y and add them to the front of the value of x. Then the ascending order I was looking for could be based on that value. After much trial and error I came up with a formula, a code snippet of python and a few added fields. By adding both an x and y geometry in long integer type to avoid any decimal places as two new fields and adding a sort field to use the field calculator, I could subtract 1 from the value of y and divide that by the value of y. That way every greater initial value of y was now less than its original lesser value of why. Confusing. This outcome had to be converted into a float type to make use of its decimal places of which the values would then be multiplied by 10 million to return it to an even integer. This part may vary depending on what or where in the coordinate system you are using. This value is then converted back to long and then that to a string. This string is then concatenated to the converted string value of x and making a reversed value of y in front of the value of x. Exactly, what I needed to for a sorting filed for my series of points. A sort field is created and the python code below fed into the Field Calculator. str(long(float(float(float(!y!)/10000)/float(float(float(!y!)/10000)-1))*1000000))+str(!x!) Using the Sort Tool on only this field arranged the drawing order to the way I needed. Applying an incrementation function to another added integer field, the labels for my points were perfect.  Up your's ESRI!
The types of projects in cultural resource management can vary greatly in scope and methodology. From monitoring construction projects, deed research, survey to full data recovery, the way in which the work is conducted can change depending on individual state or municipal guidelines, the type of permit required, the phase of work, nature of the site or district the project is in. Some jobs are similar, but every project is different. Projects overseen by federal agencies and that adhere to federal regulations, however, are pretty much always the same. For example, projects for the National Forest Service always maintain the the same methodology for a Phase IB survey. Phase IBs are almost always contracted out to private firms usually due to the large scale of the projects and additional phases are then left to actual Forest Service staff as the scope becomes more manageable and focused. Logging, trail construction or improvements and facility construction are all examples of projects that require an archaeological Phase IB survey and they all require the same methodology for testing. First a project area must be delineated into three zones of archaeological sensitivity: high, moderate and low. Zones of high archaeological sensitivity require shovel test pits to be excavated at a 15 meter interval in a rectilinear grid pattern. A shovel test pit normally consists of a 50 centimeter diameter or square hole excavated vertically through the ground in arbitrary interval provenience levels or provenience levels separated by natural stratigraphy down to what is considered to be just beyond cultural bearing strata. Each level is screened separately for cultural artifacts. Moderate zones require shovel pit testing at 30 meter interval and zones of low archaeological sensitivity require only pedestrian survey or a visual walk over with archaeologists spaced at 15 meter intervals. 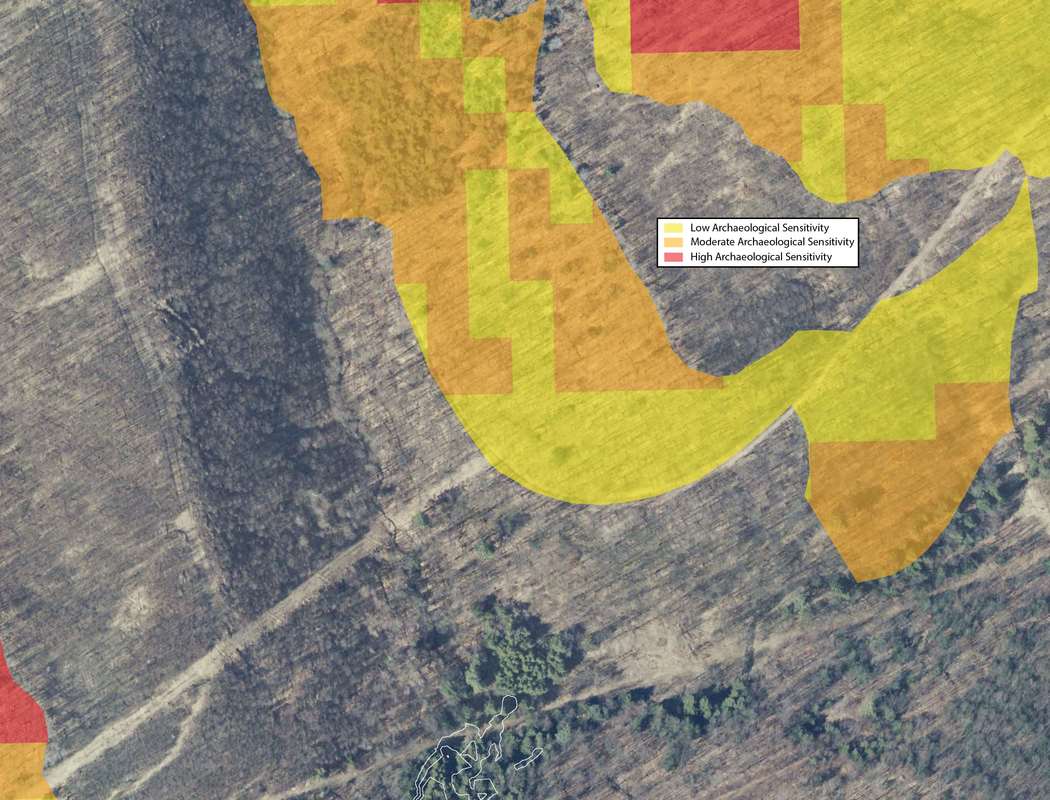 The methods for determining archaeological sensitivity vary by environmental setting but always take into consideration distance to water, soil type, slope and proximity to known archaeological resources. Areas within 100 meters of natural water courses are usually designated as high sensitivity and areas 300 meters are considered to be moderate, however; areas within those zones can be deemed low sensitivity if the percent of slope is greater than 15, or if the soil type is poorly drained. The details in GIS can be reserved for another discussion. Normally, archaeologists from each particular National Forest will develop their own sensitivity model for their forest as they know its environmental setting and existing conditions best. If one has not been developed, a statewide or regional model can be adopted if available or the contracting company will be required to develop their own model localized to the project area. Logging is common practice within National Forests. It is way to provide natural resources for the surrounding communities and the region. It is also a way to manage the forest by clearing areas with potential forest fire hazards and a way to promote new growth within the forest once the clearing is done. Logging, however, is disruptive to the soil as large machinery treads through the landscape and entire root structures are uprooted causing detrimental impacts to potential archaeological resources within the forest. A year prior to every scheduled round of clearing, the areas of impact are archaeologically surveyed. These areas of the forest are divided into small regions for clearing called Stands. Stand boundaries are mostly drawn on the basis of land forms, roadways or any other natural divide and can vary in size from about 10 to 60 acres. When an contracted archaeology firm takes on a project like this, they are provided a polygon shapefile of scheduled Stands numbering from about 80 to 100 at varying acreage and a polygon shapefile of the three tiered sensitivity zones covering the project area. GIS specialists for the company are then tasked with applying the sensitivity model to the Stands and generating shapefile point data representing shovel test pit locations respective to each zone of sensitivity within each Stand. These points number into the thousands. Each location is to be assigned a 5 digit Stand indentification number coupled with its unique accession number within each stand. The points are then converted into a waypoint file to be loaded into a Trimble Geo7X series GPS unit for sub-meter accuracy as per Forest Service requirements. In my experience as a GIS specialist for a CRM firm, having adopted this task two years ago, the process for generating these data points involved individual geoprocesses taking many arduous man hours that will be explained through the construction of a tool in ArcGIS Model Builder that now takes mere few seconds to execute. The tool accepts only two parameters, the two polygon shapefiles that are provided by the National Forest Service: Scheduled Stands and the Sensitivity Model. By inputting the two shapefiles, the tool begins by creating an arbitrary 100 meter buffer around the Stands parameter for the purposes of being able to manually shift the vertices of the lattice grid generated from the fishnet tool after the tool is run to overlay the centroid points also generated from the tool prior to clipping the lattice to the stand boundaries. The buffer is than used as a spatial template for the extent of two separate fishnets, one generating a 15 meter interval grid and the other generating a 30 meter interval grid. The fishnet tool generates a polygon or polyline grid at a specified interval and when checked will also generate centroid point for each box of the grid that can be the basis for shovel test pit locations. The 30 meter grid lattice is sent to the scratch folder as it will not be needed. The resulting 15 and 30 meter grid points are then sent to separate clipping functions. These clipping functions can not operate until parallel resulting preconditions are met. The preconditions are set by the sensitivity model parameter which first must be converted to a feature layer using the Make Feature Layer tool so that the Select tool maybe used twice upon its output. One selection would include high sensitivity attributes and the other would include only moderate sensitivity attributes. Then the two separate Clipping processes may begin with the "Use only selected features" box checked. The 15 meter interval Fishnet points will be clipped to the selected high sensitivity feature and the 30 meter points clipped to the selected moderate sensitivity feature. 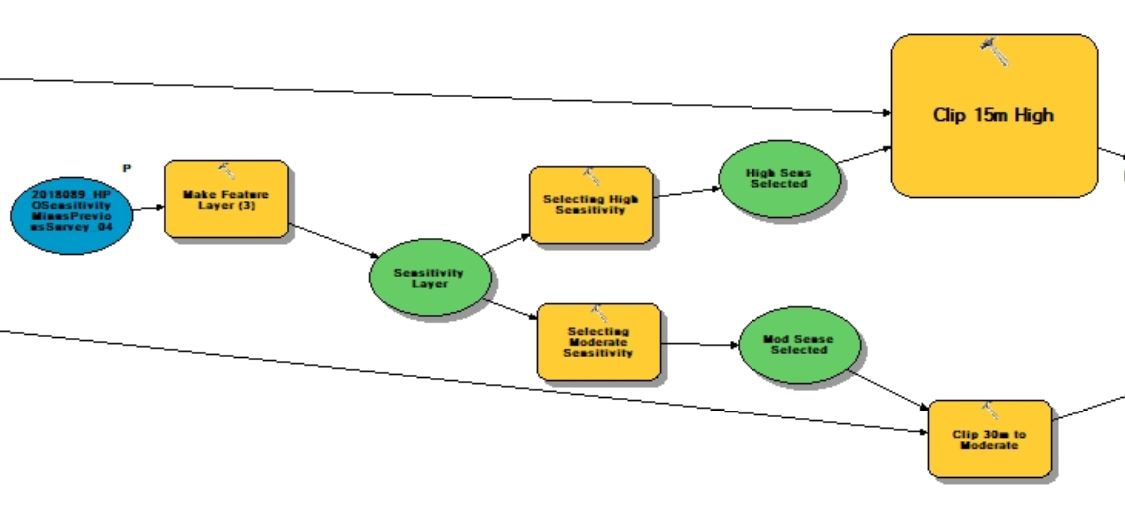 The results of each clipping process are then merged together using the Merge tool into one feature layer that consists of 15 meter interval points coinciding with high sensitivity zones and 30 meter interval points coinciding with moderate sensitivity zones. This output contains the number of points that will represent the number of shovel test pits required to fulfill the permit for clearing the scheduled Stands. The next process in the function is the Add Field tool. This will add an attribute field to the current feature that will represent each point's unique identifier within the Stand. The added field is an integer numeric data type that the result of which will again, be made into a new feature layer using the Make Feature Layer tool so hat it may be selected upon based on an iteration of the the individual Stands within the Stands layer. Here, the current layer is stopped until another precondition is met from a parallel running process that also involves the input parameter of the Stands shapefile. This part of the parameter is fed into a Select by Row iterator provided as a built-in function of Model Builder. This will iterate, like a for loop, through each record (Stand) after being converted into a feature layer. Every iteration will be input into the Select Layer by Location tool which will then select the inputted paused for preconditioned STP points layer as the taget and the selected Stand layer as the source. Each selected set of points will then be sent to the Calculate Field tool which, through a python expression, will add from low north to high east consecutive numbers the points layer per Stand. The expression is as follows: rec=0 def autoInc(): global rec if rec==0: rec=1 else: rec+=1 return rec Now every point within each Stand is assigned its own identifier in the drawing order that is easy to interpret in a field map. To assign the the Stand identifier to each point the Stand parameter through the iteration tool is then fed into the Spatial Join tool that takes the STP points layer as the target and the Stand as the join feature. Now every point has its respective 5-digit Stand code obtained by the attribute table from the Stand layer. Next, using the Delete Field tool, all fields existing in the resulting layer are deleted except for the the auto-incremented numbers field and the Stand identifier field. The Add Field tool is than used to make a string field of 10 characters called "test". The result of that is then fed into the Calculate Field where a simple concatenation python function <!STAND_ID! + "-"+str(!num!)> populates the field with every point's unique identifier-"#####-#". Now, by opening a single tool and inputting just two parameters,, a task that, in the past, took several hours now takes just under 45 seconds. 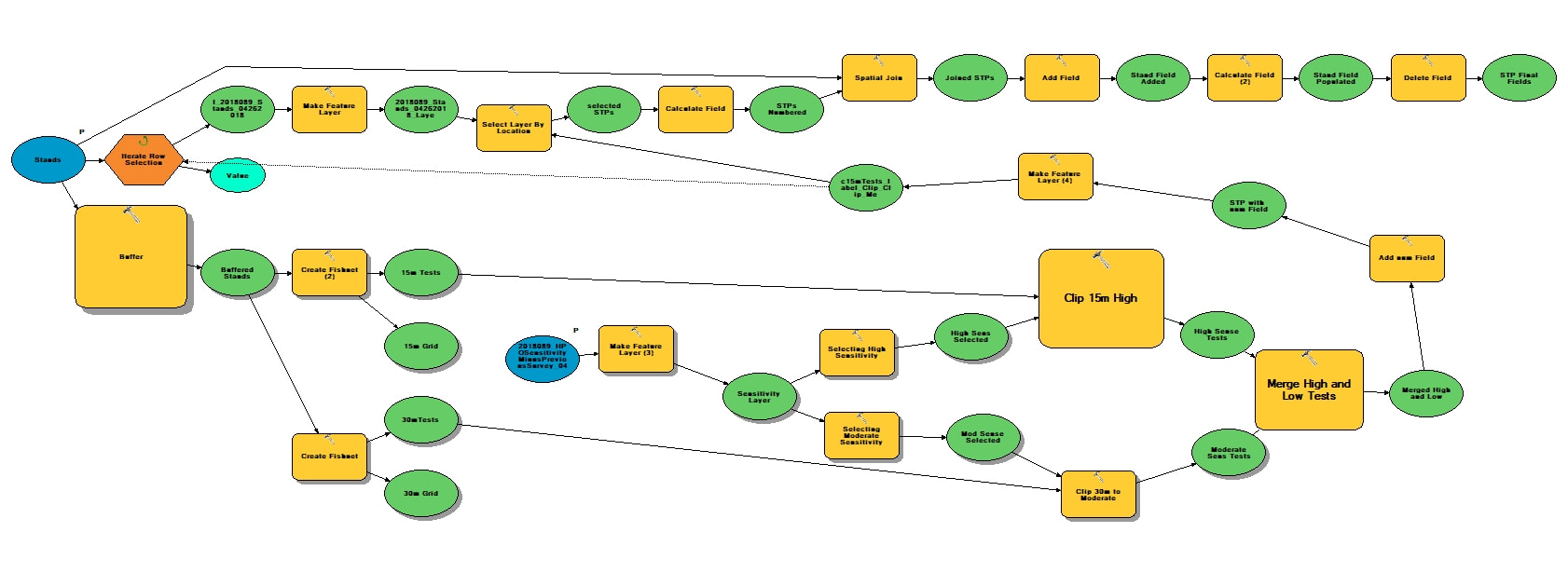 One of the most common ways to begin an archaeological investigation in the Eastern United States is in the form of a Phase IB survey. After an initial assessment of the project area, a IB may take the form of a pedestrian survey in which archaeologists comb the landscape in an evenly spaced formation looking to identify site indicative artifacts on the surface of the ground. This method usually only occurs if environmental settings consisted of tilled earth or a barren landscape. The other method would be to perform a series of evenly spaced shovel test pits in a grid fashion blanketing the project area or areas of assumed high to moderated archaeological sensitivity. The purpose of a shovel test pit (STP) is to sample a project area at evenly spaced intervals or at judgemental locations. An (STP), on average, is likely to be an approximately 1.5' diameter hole excavated in the ground to about one meter or 3.5' before impasse. Levels of provenience can either be determined by the natural stratigraphy or by any arbitrary increment. An STP in shape, can be round to square, but in any way it is best represented as point geometry type in terms locational sampling and mapping. The spacing of a test pattern grid is usually 50 feet or 15 meters and as seen in the example below. 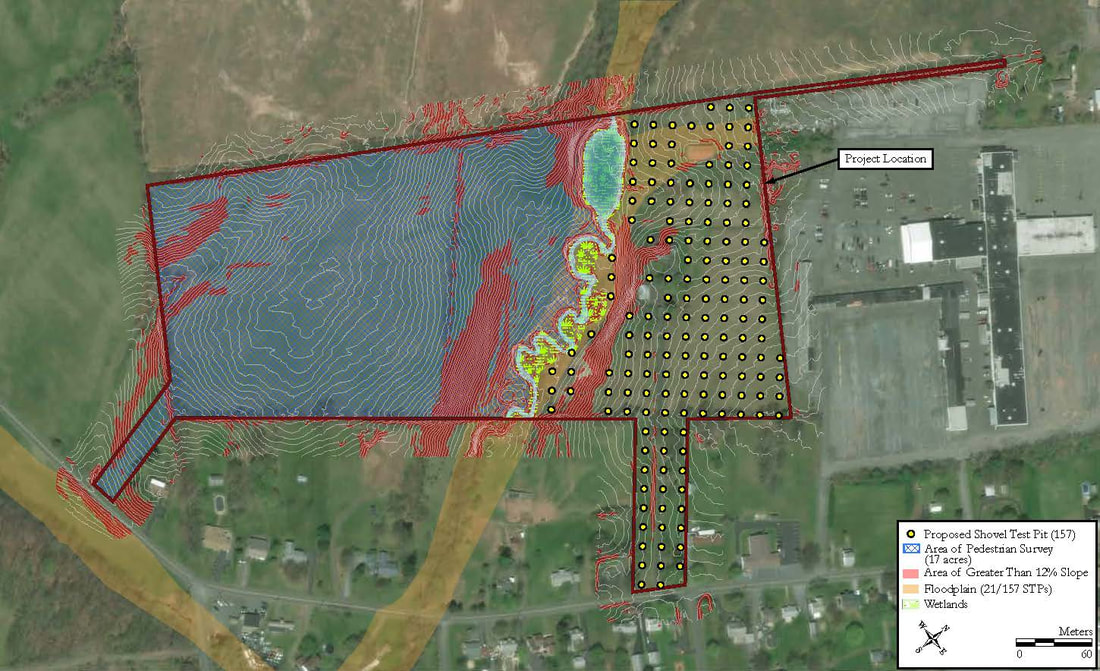 In the Olden Days, prior to survey, plots like these would be produced by hand with ruler and pencil on a set of scaled project plans and used in the field as a basis for the locations of shovel tests. With the advance of GIS software it became easier to produce a testing grid on a map by georeferencing project plans and using software tools, such as in ArcGIS, the Fishnet tool to produce a grid formation over a project area. The Fishnet tool was originally designed to create rectangular sampling polygons or polyline divisions at specified dimensions over a specified location. The output also includes center point data for every sampling polygon produced. The point feature can then be spatially moved, in an editing session, to meet the vertices of the intersecting lines or polygons to make a grid testing pattern precisely like ones used in a Phase IB survey. The points generated from this process come with zero attributes and no field to label each test. There are generally two ways to label or assign names to shovel test pits. One way is alphanumerically, in which STPs are assigned number, letters or a combination of the two across the testing grid. The other naming convention is to assign an arbitrary system of local grid coordinates to the testing pattern usually by northing and easting and always at the unit of measure and intervals on which the testing pattern was created such as N50/E50 and so on. 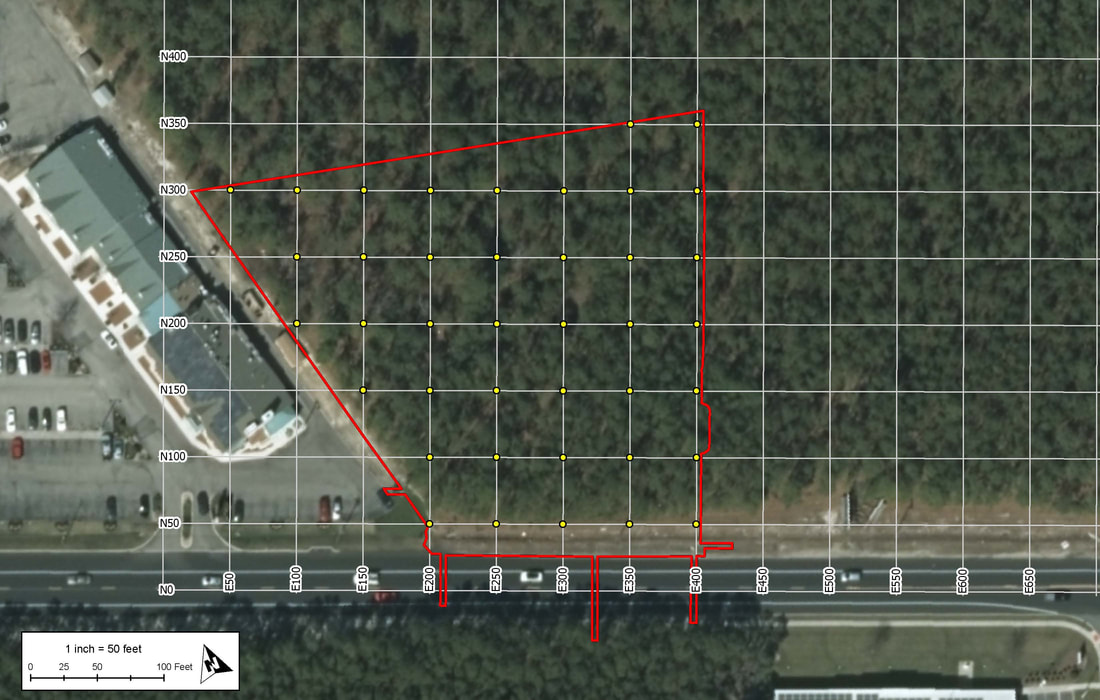 The latter is the preferred way for archaeologists conducting the survey in the field for a few reasons. The first is that by labeling only the grid lines there is no need to clutter up the map with labels for every test. Larger projects than the example above are displayed at larger scales thus shortening the perceived interval of the grid leaving little room for labels or notations on the map. Another reason that is that every STP name is also a locational descriptor of where the test is in the project area which is useful when referring to find spots. It is also helpful in keeping track of STPs prior to and before excavation, especially if you find yourself without a map. When a grid is labeled numerically, the direction of the testing transect may not always line up with the direction of the number increments and from test to test would be cutting across large and sometimes unpatterned number intervals.
The coordinate naming system, however; was not the preferred way for GIS and graphics specialists at the CRM firm I work for. It is easy to generate incremented numbers for every point in the testing grid using the snippet of python code, but a little more tricky to label every line in the grid and even more tedious to label every point in a shapefile with a name like "N2050/E1400" especially on larger projects that may have as many as 100 transects in either direction. If not entered manually test by test, shapefiles for these kinds of shovel tests usually were left unlabeled in their attributes and therefor the results of the STP were left out of the attribute table as well. For report graphics every grid line was labeled in post production, as task sometimes taking several hours to complete. Upon joining the GIS team, it was my goal to figure out a way to solve this problem. I had to develop a new way of thinking about this generated point data. Instead of having the fishnet tool create a series of evenly spaced points without attributes for you, why not plot the points yourself using grid coordinates as XY data. In Microsoft Excel, I made a a CSV of three fields. The first field was for the Northing value, the second for Easting and the third for a concatenation of the two values that include a letter "N" at the beginning and a "/E" dividing them. The table had to be big, big enough to accommodate project areas that could be 10,000 feet in either direction. Using the powers of the software I was able to quickly produce a table of point values starting at 0,0 for over 40,000 points and the concatenation of the point values for name assignment. This was done at increments of 50 for projects that require intervals in feet and one with increments of 15 for projects that require intervals in meters. In ArcMap I plotted the tables as CSV events in a state plane coordinate reference system for New Jersey in feet and Pennsylvania North and South in meters. The points plotted beginning at the 0,0 point of the projected CRS and the events were exported as shapefiles to their respective coordinate reference systems. For grid lines I still needed to rely on the fishnet tool but by selecting vertical lines apart from horizontal lines and using the python defined auto increment function in the field calculator was able to increment them according to their interval spacing instead of by 1. A string concatenation in an added field called "Transect" allowed me to include and "N" for horizontal lines and an "E" for vertical lines. The resulting grid was moved to be placed with the line vertices matching precisely with their corresponding points plotted from the CSV. Now there is a template on the company server that consists of shapefiles of grid lines and points for the three most common projected CRSs. They can be brought into any GIS project and be positioned and oriented over a project area with the label assignment for points and lines already complete. Results from the shovel tests can now also be quickly joined from a Shovel Test Pit Log, in all saving the company several hours per project. |
 RSS Feed
RSS Feed
